For those of us who didn’t study computer science, the topic of AI can be difficult to grasp.
Thanks to sci-fi villains, high-profile twitter meltdowns and far-off doomsday predictions, most of us are more likely to treat AI with a kind of mild suspicion than to see the more ordinary reality:
Artificial Intelligence is basically a trial and error computing process.
While AI models themselves can be incredibly complex, the way these models function to perform set tasks and improve based on feedback is easy enough to follow.

With that in mind, we’d like to spend a few minutes demystifying our own AI digitization process so you can better understand the work that goes into Enote, and how it creates a better musical future for you.
Understanding the challenge
Our goal is simple – bring all of the world’s sheet music into a native digital format.
This will let us give musicians everywhere unprecedented access to professional scores, and create advanced functionality that makes preparing, practicing and performing music easier.
The catch? There is a lot of music out there – all unique and almost always complex. Even with an army of music engravers, it would take multiple lifetimes to transcribe all of the scores and parts that make up our musical heritage, which means we’d never see our vision come to life.
That’s where the power of AI comes into play.
Instead of relying on humans to do the manual work, we’ve created custom computer systems capable of completing the task with near perfect accuracy. These systems do the heavy lifting, then hand over to our experts to fine tune the results.
In other words, AI makes it possible to transcribe mountains of sheet music without an army of volunteers, and reduces the time we need from centuries down to months.
So how does the process work? Glad you asked…
Our step-by-step process
Step 1 – Train AI models to complete the manual task
To digitize sheet music, we need to train our AI to recognize musical elements and understand the relationships between them.
Both of those are much easier said than done.
Recognition relies on computer vision, which involves teaching computers to recognize distinct shapes. This is difficult as computers need a strong frame of reference to understand visual differences that are clear to humans.
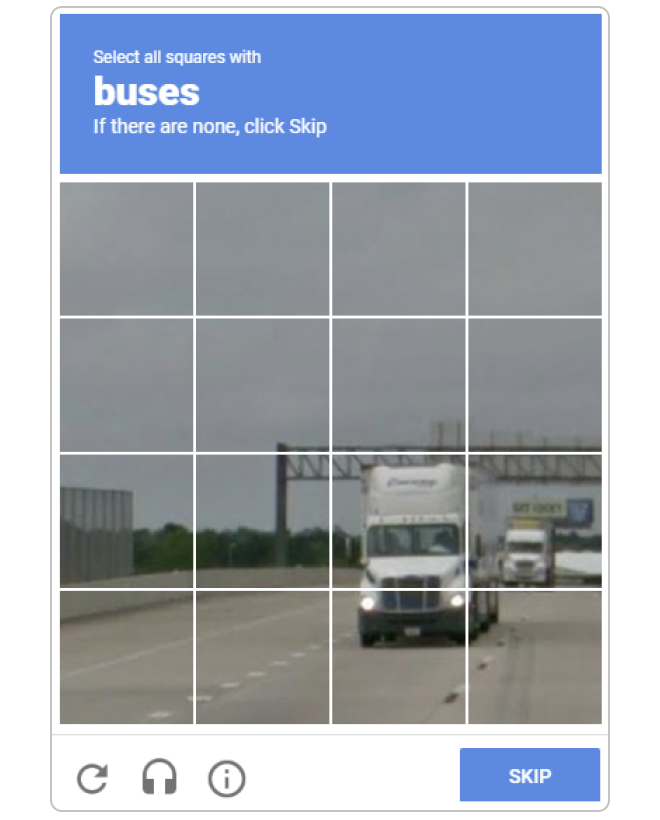
Online Captchas are a great example of this. It’s easy for you to see that this is a truck and not a bus, but computers struggle to tell these similar shapes apart.
Music notation adds the complications of overlapping elements with no color differentiation and imprecise ink prints, creating the type of challenge that gets great AI engineers excited.
Then we have the relationships between elements. There are an almost infinite number of ways that music notation can be organized, with thousands of rules dictating how each element relates to the others. These rules are generally grounded in logic – but can sometimes require a leap of faith.
Take a look at the measure below. Context tells you that the small fioritura notes cover the same rhythmical duration as the last three quarter notes in the lower staff, but how does one tell a computer to squeeze 18 “eighth notes” into that short section?

Thanks to thousands of hours of work by some of the world’s leading AI engineers, we’ve developed systems that excel at these two tasks. But the systems themselves are nothing without music…
Step 2 – Source the best material
With dozens of editions available for most public domain works, finding the best source material is essential to the quality of our library.
We have a whole team of musicologists dedicated to just this task. They assess every available version of each work, decide on the most reliable editions for processing, and provide consistent metadata that ensures our filtered searches and work pages are accurate.
This is already happening for all public domain works, and we plan to work with copyright holders and publishers in the future to make contemporary compositions and comparative critical findings available to Enote users.
Step 3 – Recognize, reconstruct and encode
We then run this material through our AI pipeline, which recognizes each individual musical element. This recognition happens for every measure and instrumental part, meaning tens of thousands of elements are processed in most pieces.
After recognition, the elements and their relationships are reconstructed and encoded into MEI – an open source file format for better digital music encoding. We contribute heavily to this format to enable our own work, and to help create a more robust standard for the music community.
Step 4 – Visualize the music
Our digitization process is now technically complete, but thousands of lines of XML code aren’t very useful to a performing musician.
Instead, the encoded material is visually rendered in real time using the Verovio Engraving Library – another open source project we are helping extend for everyone.
This dynamic translation from encoded information to visual information is what makes our scores flexible, allowing users like you to control variables like screen dimension, engraving style and notation size as you need.
Step 5 – Find Errors. Train and expand. Repeat.
AI-driven processes like ours don’t start off perfect. Instead, they rely on training and continual enhancements to get better and better over time.
The 99.9% accuracy we currently achieve is technically astounding, but in practical terms it means that one error comes through every 1,000 musical elements. Some of these errors are too small to notice, but others can ruin the whole experience:
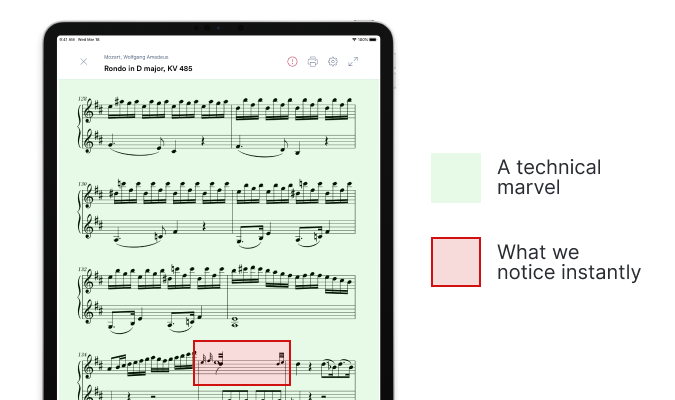
Thankfully, our team close this error gap a little every day by improving our models, enhancing our reconstruction process, and extending the capabilities of our encoding and rendering platforms.
These efforts fix the root causes of misprints reported by users, which also instantly removes most similar misprints from our library, and all but eliminates the issue for future reconstructions.
While that’s great for making effective progress, the hands-on nature of fixing root cause issues means that a lot of time can pass between an error report and the fix appearing in our library. We don’t love that, so are working on a manual correction process to fix individual misprints faster, plus a score editor that will let you adjust your own score content in real time.
Where to from here?
Though progress can seem slow from outside our office, we’ve been making huge steps forward in the months since our public launch.
By this time next year we expect to have 10x as many works in our library, and will have drastically increased the accuracy of our digital scores with the help of system improvements and your error reports.
Until then, we can only thank you for caring about our vision and being part of the journey. We’re committed to creating a platform that will benefit the global music community – and every error report, feature suggestion or app recommendation gets us one step closer to this goal.